Skip to content

 How to sync data between Coda docs (and Google Sheets) using Google Apps Script
How to sync data between Coda docs (and Google Sheets) using Google Apps Script
3 methods to do a one-way data sync in Coda and Google Sheets

May 2020 update: Published two scripts to sync from Coda to Google Sheets or from Google Sheets to Coda. See for details.
Feb 2020 update: If you are using the in Google Apps Script, delete the word each from and of the script.
Importance of sharing data
You have a master spreadsheet with some sensitive data, but want to share some of that data with a client, employee, or vendor. You obviously can’t share the entire spreadsheet because then the other party can see your sensitive data. I’ve seen this scenario over and over again in various workflows, and there are some solutions that solve this problem…but they’re not perfect. So what do you do?
If there is software that exists specifically for your industry, then you’re in luck. Chances are that specialized software has built in data sync features that allow you to see the data that is important to you, but then you can share a filtered view of that data with your client or patient. The other party most likely has to set up a login on the software you use, or download an app to see their data.
Then there’s the rest of us.
We spend our lives in Excel spreadsheets and Google Sheets, and needs simple ways to share data between the files. In this article, I’m going to discuss:
If you want to skip right to the solution, here is the , and the . Or just watch the video below.
First off, what is Coda?
Coda is a real-time collaborative doc (similar to a Google Doc) that includes the power of spreadsheets and databases in one tool. With Coda, you’re able to build applications (without code) that build workflows for , taking , and even organizing for your friends. See the video below if you’re more of a visual learner:
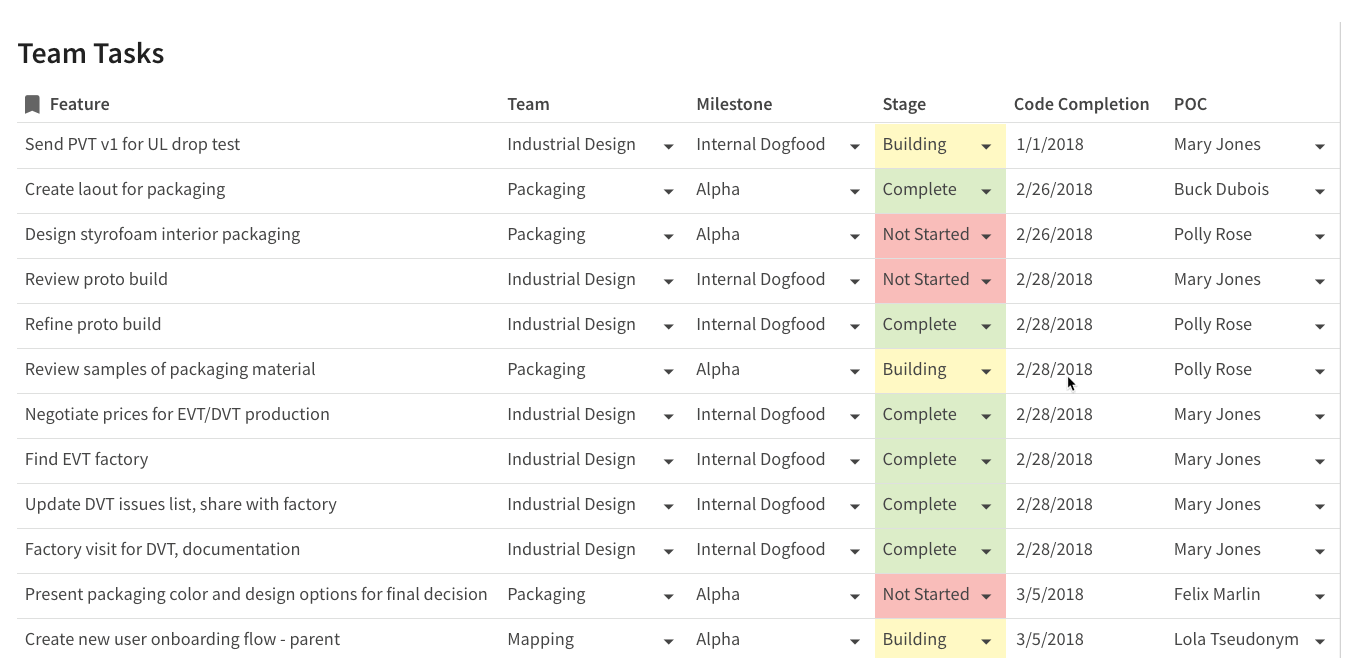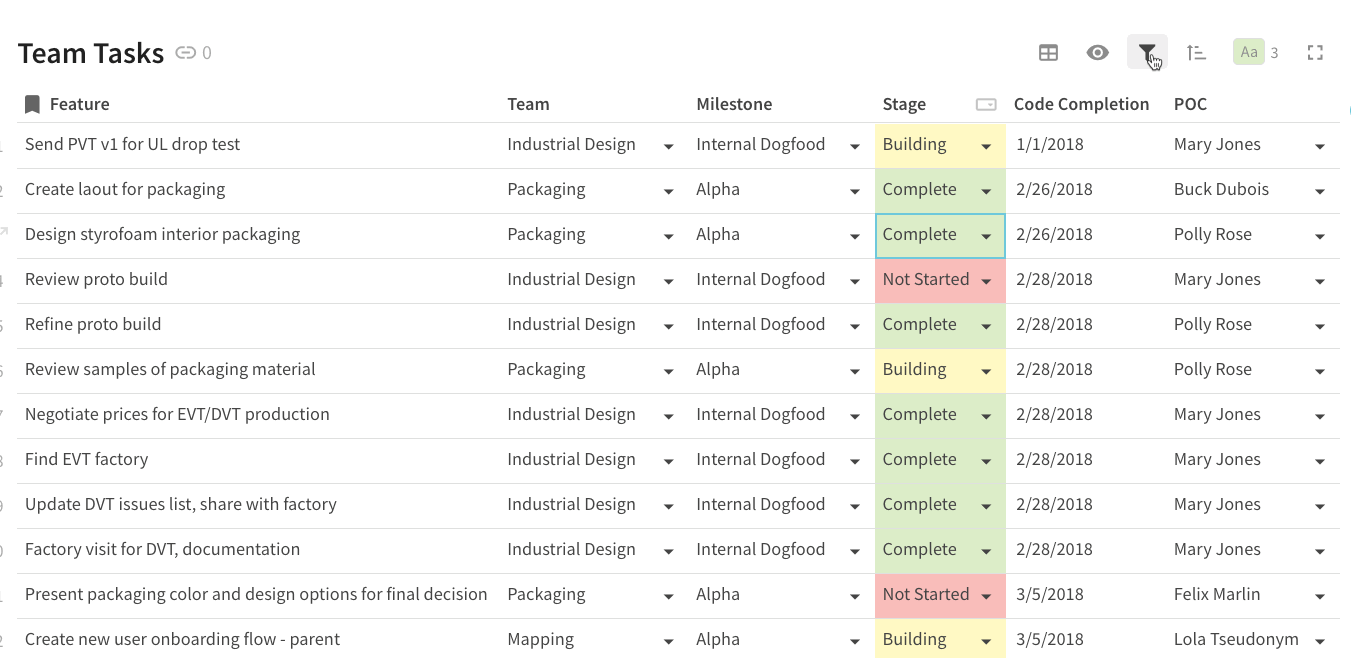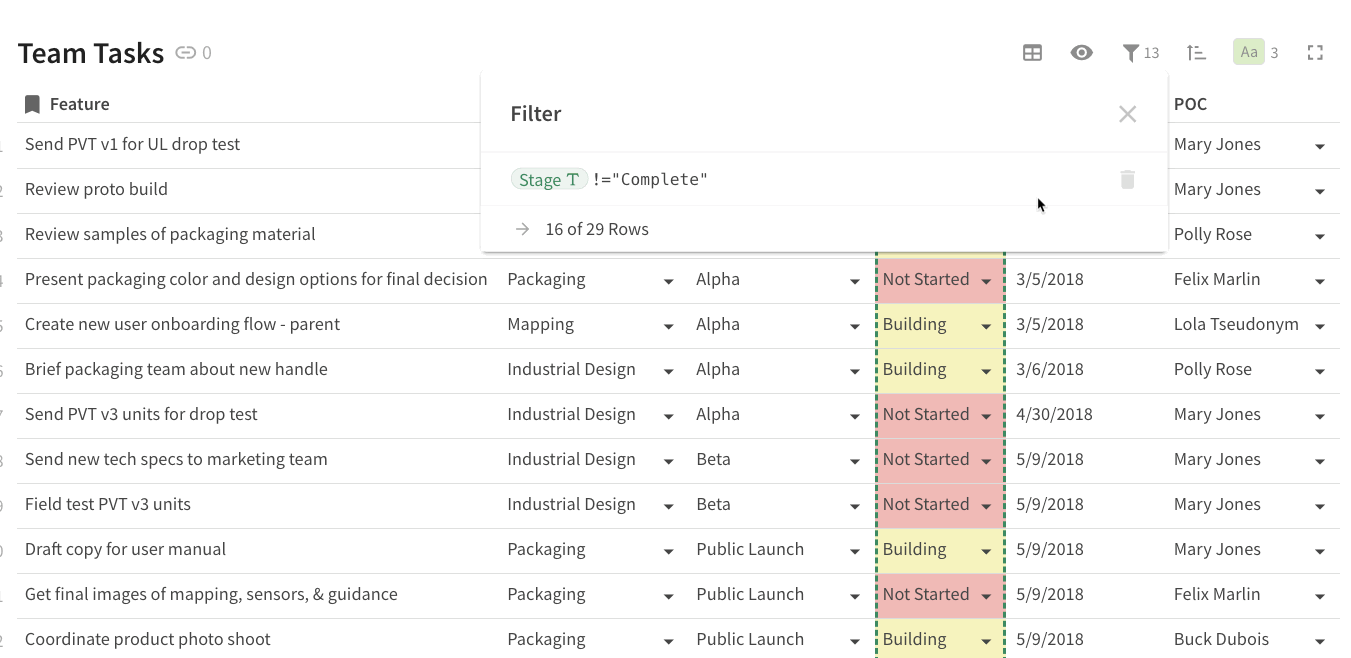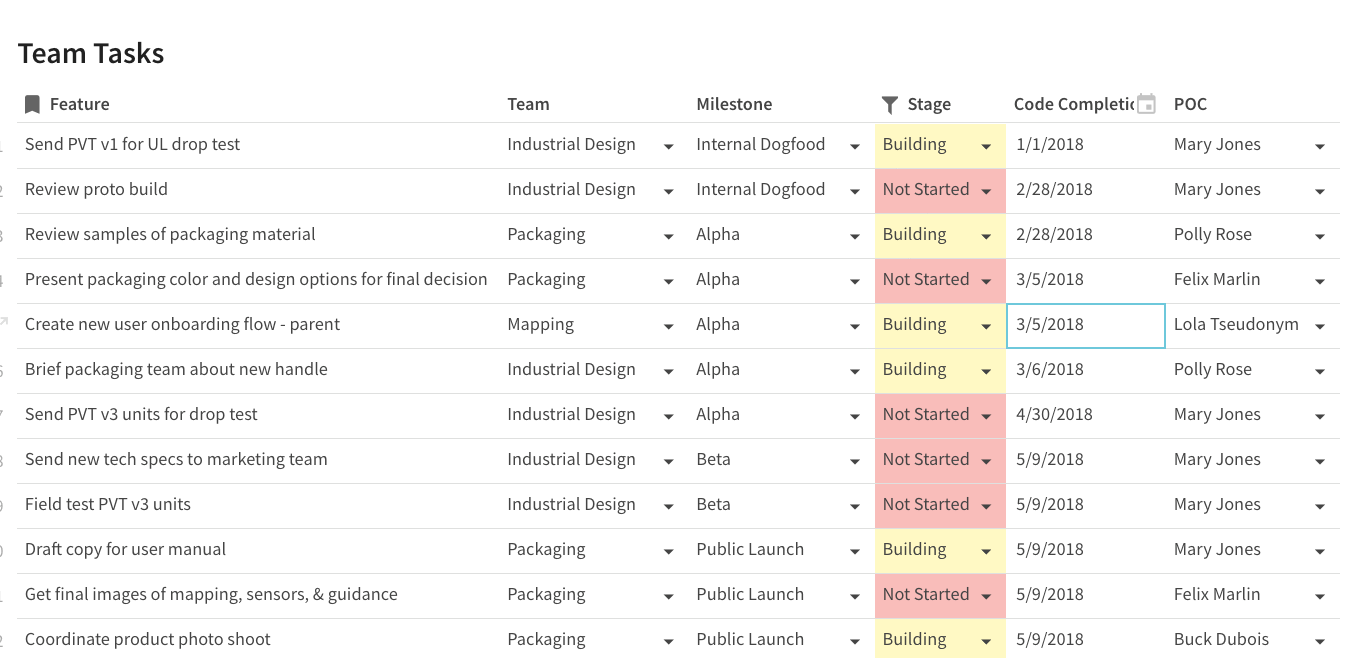
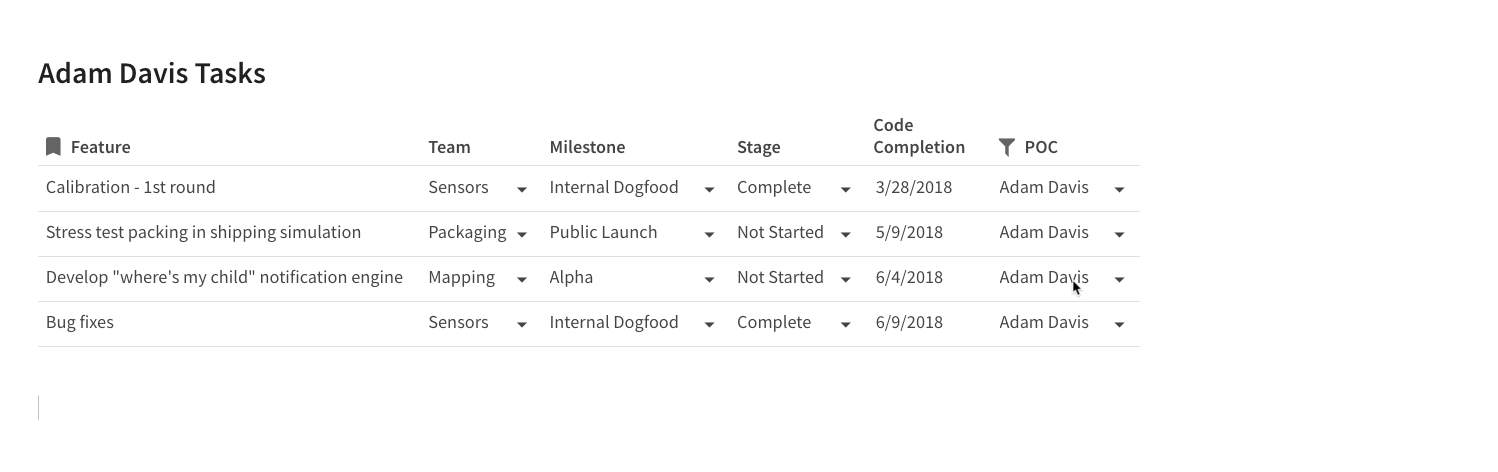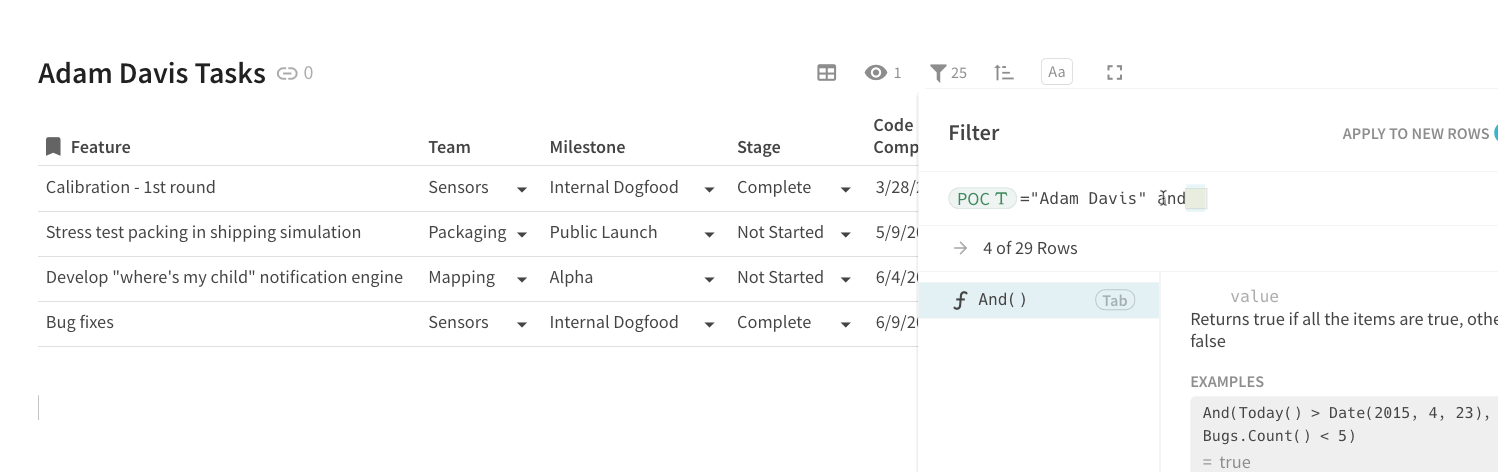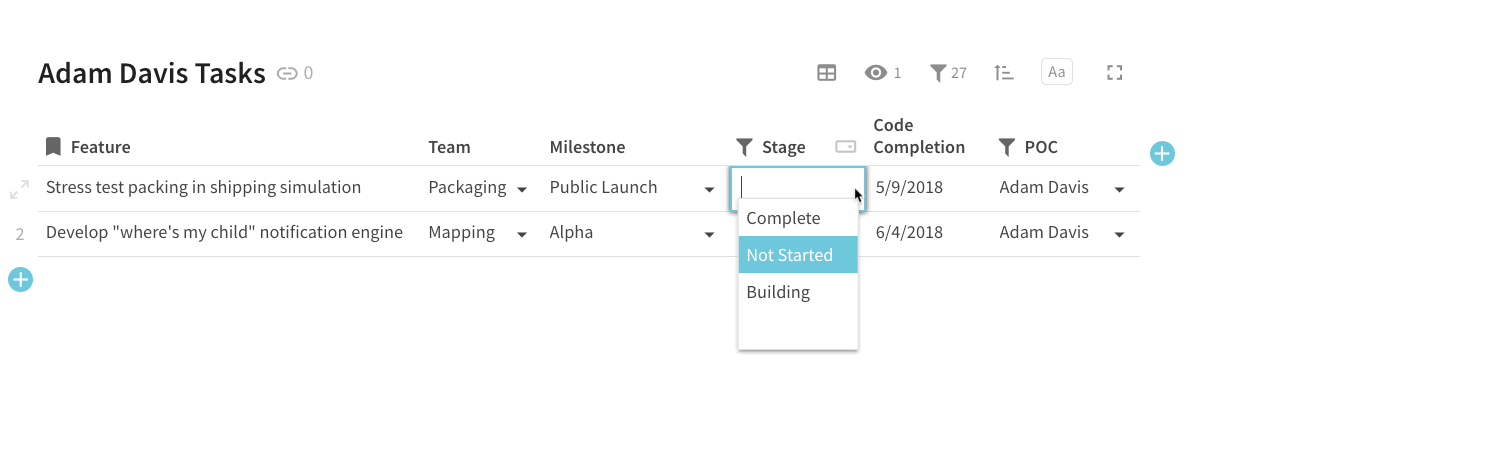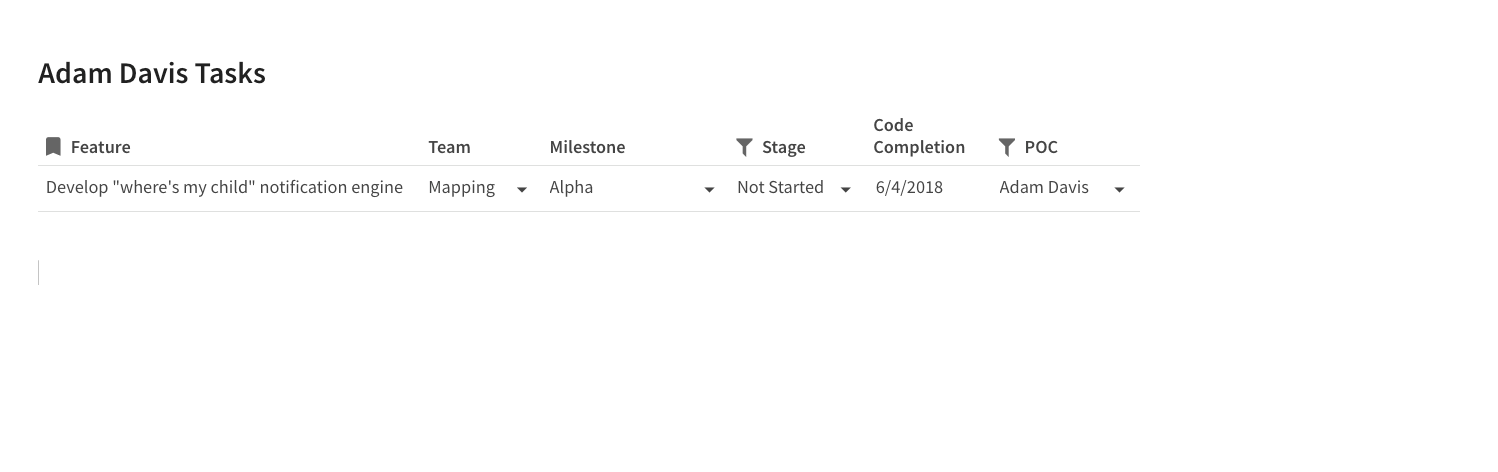
At the heart of Coda are tables of data. Tables in Coda look and feel like a grid of cells in a spreadsheet, but they have names and act more like databases. Here is a table of team tasks with typical columns you would need for managing tasks for a project:

Table of project tasks in Coda
Filtering data that’s relevant for you
If you are the project manager, this list could get pretty long so what most project managers would do is of the tasks filtered to just tasks that have a Stage of “Not Started” or the “Industrial Design” team would create a view of the tasks just filtered to their team.
Many users in the Coda community want to sync the data from a master task list above to a separate Coda doc. Why? To create an even cleaner view of the tasks that doesn’t include the other sections of the “source” doc. Some common workflows outside of project management I’ve seen:
Enter Google Apps Script
You can integrate all the various apps you use from Google (e.g. Gmail, Google Sheets, Google Docs) using Google Apps Script. Coda has a library you can use in Google Apps Script, which means you can integrate data from Coda with other Google apps (and vice versa).

I find that using the is easiest with GAS, but you can also use Python or a Unix shell. What I like about using GAS for syncing tables in Coda docs together is that you can easily set up a so that your script runs every minute, hour, day, etc. If you are using Google Sheets, however, you can use that fire your script when there is a change to one of your Google Sheets.
Setting up your Google Apps Script
If you follow along with the , you’ll pretty much get the one-way sync working so that data from your master Coda doc (which I’ll call the source from now on) is one-way synced to another Coda doc you create (the target doc). See the original script in .
The main function you need to run is oneWaySync() and the table from your source doc will get synced to a table you define in your target doc. After playing around with this script, I noticed there are a few things we can do to make the script more robust to solve more complicated workflows and data sync scenarios.
#1 Sync multiple tables in the source to multiple tables in the target
If you look at the way the script is structured, it assume two things:
This is the part of the script where you define your source and target tables and the syncSpecificTable() function syncs each of the source tables with your target table:
SOURCE_TABLES = [
{
doc: 'TO UPDATE',
table: 'Source Table',
},
];
TARGET_TABLE = {
doc: 'TO UPDATE',
table: 'Target Table',
};
TARGET_TABLE_SOURCE_ROW_COLUMN = 'Source Row URL';
function oneWaySync() {
for each (var source in SOURCE_TABLES) {
syncSpecificTable(source, TARGET_TABLE);
}
}
If we look back at our project tasks table, you most likely have one “master” list of tasks, one “master” list of team members, and want to sync those to individual tables in the target doc. The script assumes you have multiple project tasks table that you want to combine into one table in your target doc:

Sync multiple source tables to one target table
I argue that this is not the most common pattern in the Coda docs you’re looking to sync. Something I see with a lot of our users is this pattern:

Sync tables one-to-one
In order to do this, we have to edit the script slightly to account for multiple source tables and multiple target tables. I didn’t want to change the data structure needed for the syncSpecificTable() function, so instead created an array of arrays of doc and table key-value pairs so that the 1 function can loop through each element in the array and reference the source doc and table via the 1st element and the target doc and table via the 2nd element. In the script below, table[0] and table[1] represent these elements:
SOURCE_DOC_ID = 'TO UPDATE'
TARGET_DOC_ID = 'TO UPDATE'
var TABLES = [
//1st table to sync
[
{
doc: SOURCE_DOC_ID,
table: 'TO UPDATE', //1st table from source doc
},
{
doc: TARGET_DOC_ID,
table: 'TO UPDATE', //1st table from target doc
}
],
//2nd table to sync
[
{
doc: SOURCE_DOC_ID,
table: 'TO UPDATE', //2nd table from source doc
},
{
doc: TARGET_DOC_ID,
table: 'TO UPDATE', //2nd table from target doc
}
]
];
function oneWaySync() {
for each (var table in TABLES) {
syncSpecificTable(table[0], table[1]);
}
}
This may not be the most efficient or prettiest way of setting up multiple tables to sync, but it works :).
#2 Deleting rows in the source table should delete rows in the target table
If you delete rows of data in the source table, wouldn’t you want the rows to also get deleted in the target table? One way I’ve seen this being done in current data syncs between Coda docs is in the target doc so that any rows from the source that are supposed to be “deleted” will just get filtered out from the target doc.
For instance, here are a bunch of tasks from the source table that are completed and should be “deleted” from the source table. You can apply a filter to the source table so that these rows get filtered out:
Filter “completed” rows from your main tasks table in the source doc
Then, in your target table, you can filter out those same rows that have been marked as “Complete.” You’ll notice that in this target table, I’m only interested in the tasks that are owned by “Adam Davis” (he has 4 tasks in various stages):
Filter “completed” tasks in target doc for tasks owned by “Adam Davis”
This pattern only works if there is value you know you can filter on in the table that would remove rows from your table. In many cases related to project management, the project manager might just delete the row entirely since it’s an irrelevant task, they made a mistake with the data entry, or they just want to reduce the number of rows in the main table. The script currently would not allow for deleting rows. If you have 10 rows in the source table, those same 10 rows would show up in the target table once the sync happens. If you delete 3 rows from the source table, there would still be 10 rows in the target table (but only 7 rows in the source table).
In order to delete rows from the target table, we need to utilize two resources available to us in the Coda API:
The browserLink is a super useful identifier for doing the one-way sync because it also gives us the ability update rows if there has been a change in the source table. We call this an when you want to either insert or update a row. In the main syncSpecificTable() function of our GAS script, I add the following code to:
var targetRows = CodaAPI.listRows(target.doc, target.table, {limit: 500, useColumnNames: true}).items;
targetRows.map(function(row) {
if (sourceSourceRowURLs.indexOf(row.values[TARGET_TABLE_SOURCE_ROW_COLUMN]) == -1) {
CodaAPI.deleteRow(TARGET_DOC_ID, target.table, row['id']);
}
});
The sourceSourceRowURLs variable is an array of all the browserLinks from the source table.
Putting it all together
A few notes about the final GAS script to sync your tables together:
Instructions to run script
and
(the doc ID is the random string of characters after the _d in the URL of your doc
The Coda doc ID is everything after the “_d”
4. Get the table ID from the source doc and paste it into , and get the table ID from the target doc and paste it into . If you have more than one table to sync, you’ll see lines
and
to sync that table.Getting the table ID of a doc
Getting the table IDs is super annoying right now (I plan on building a tool to make this easier). In the meantime, you can use the printDocTables() helper function in and replace the TARGET_DOC_ID in with SOURCE_DOC_ID depending on which doc you’re looking at. Run that function, and check view the Logs in GAS to get the table IDs (the all start with grid-):
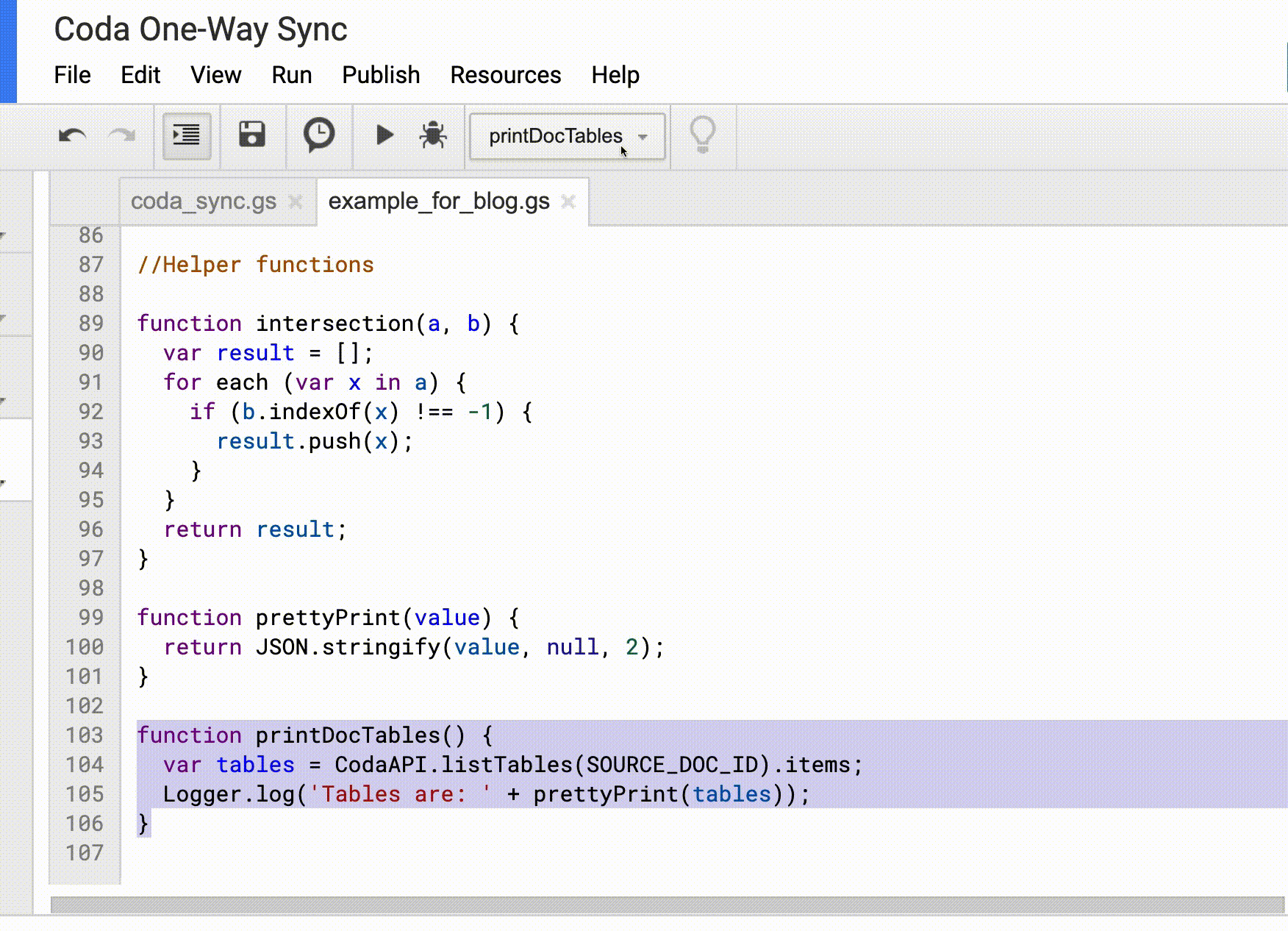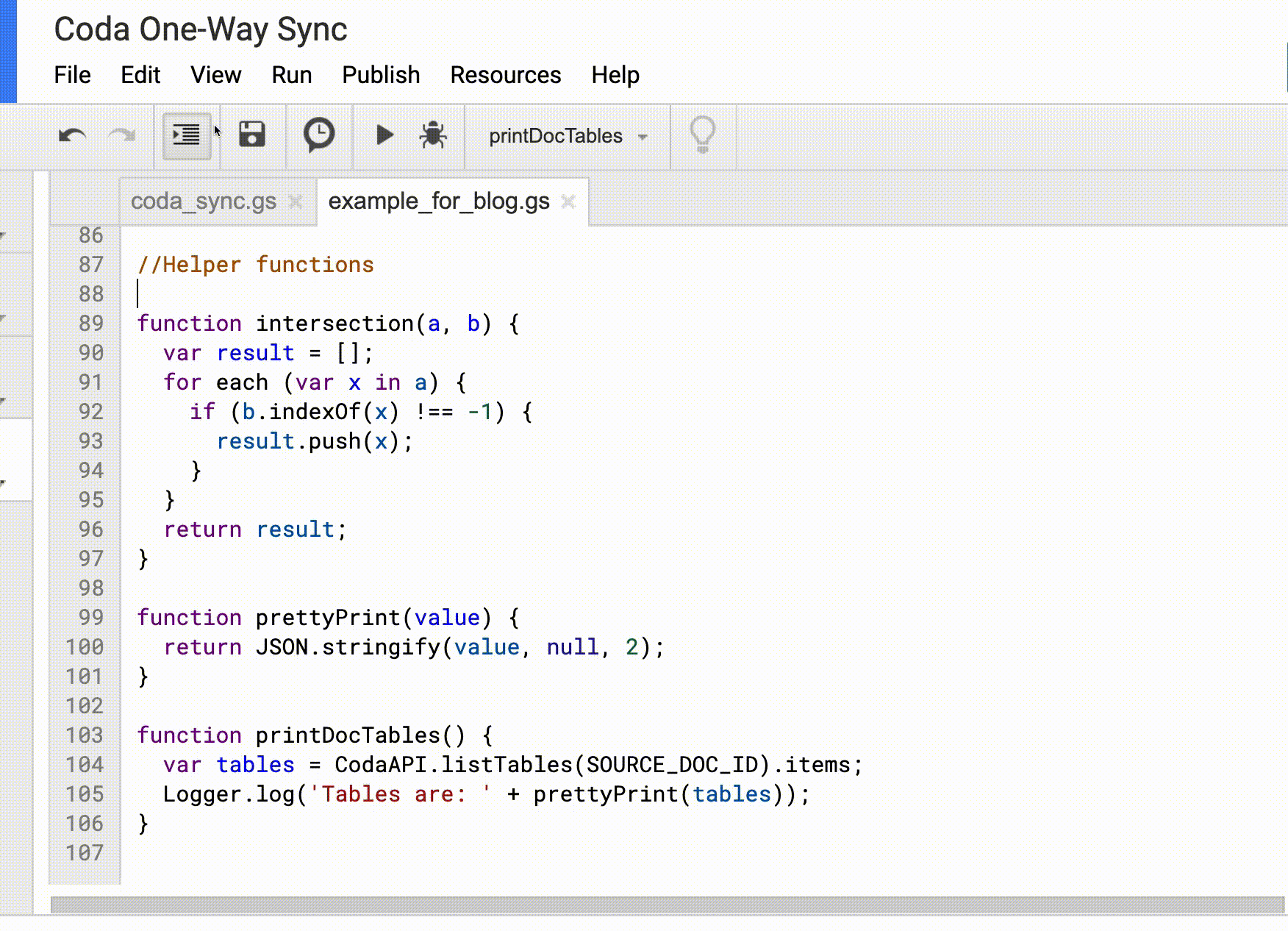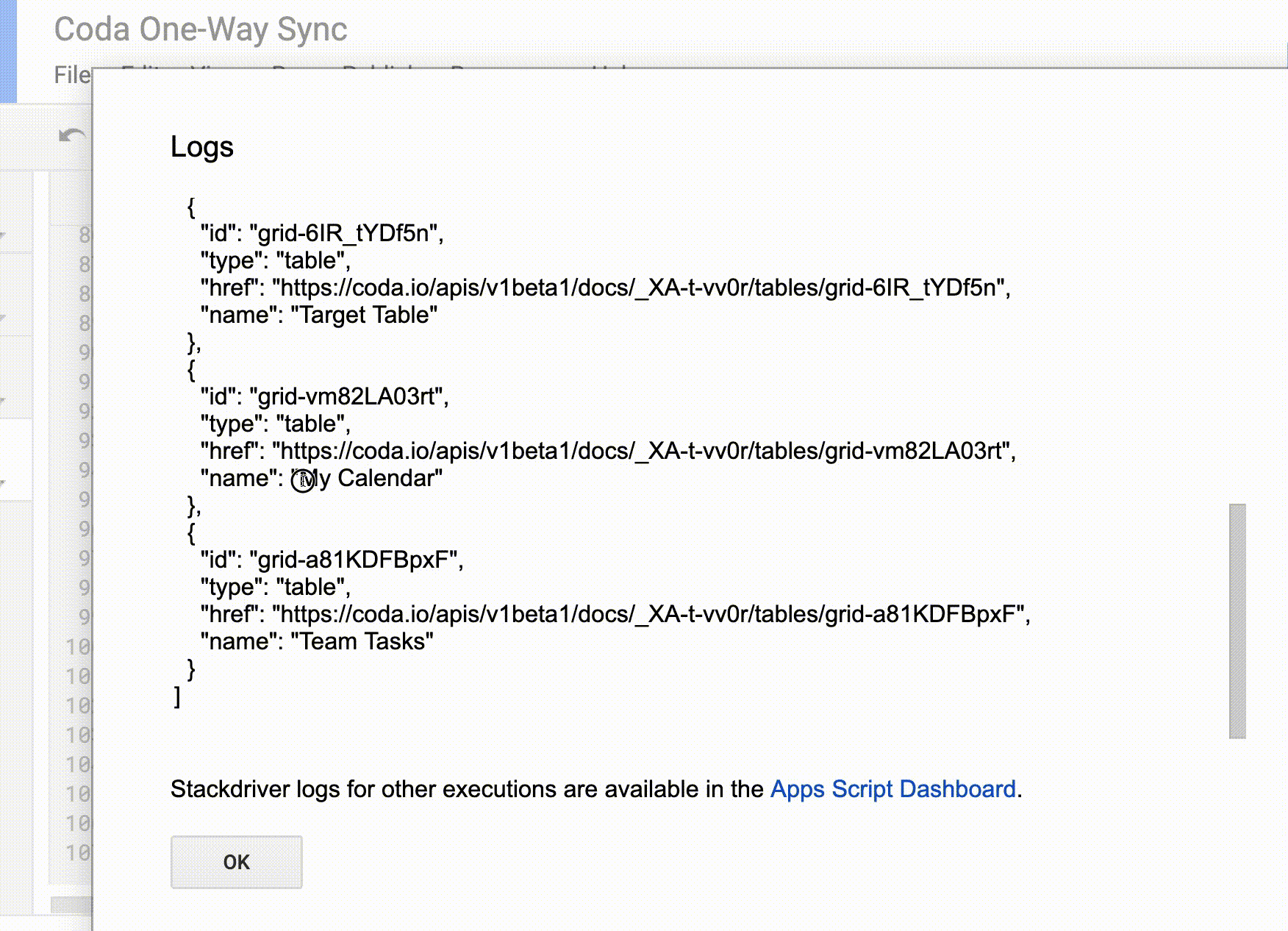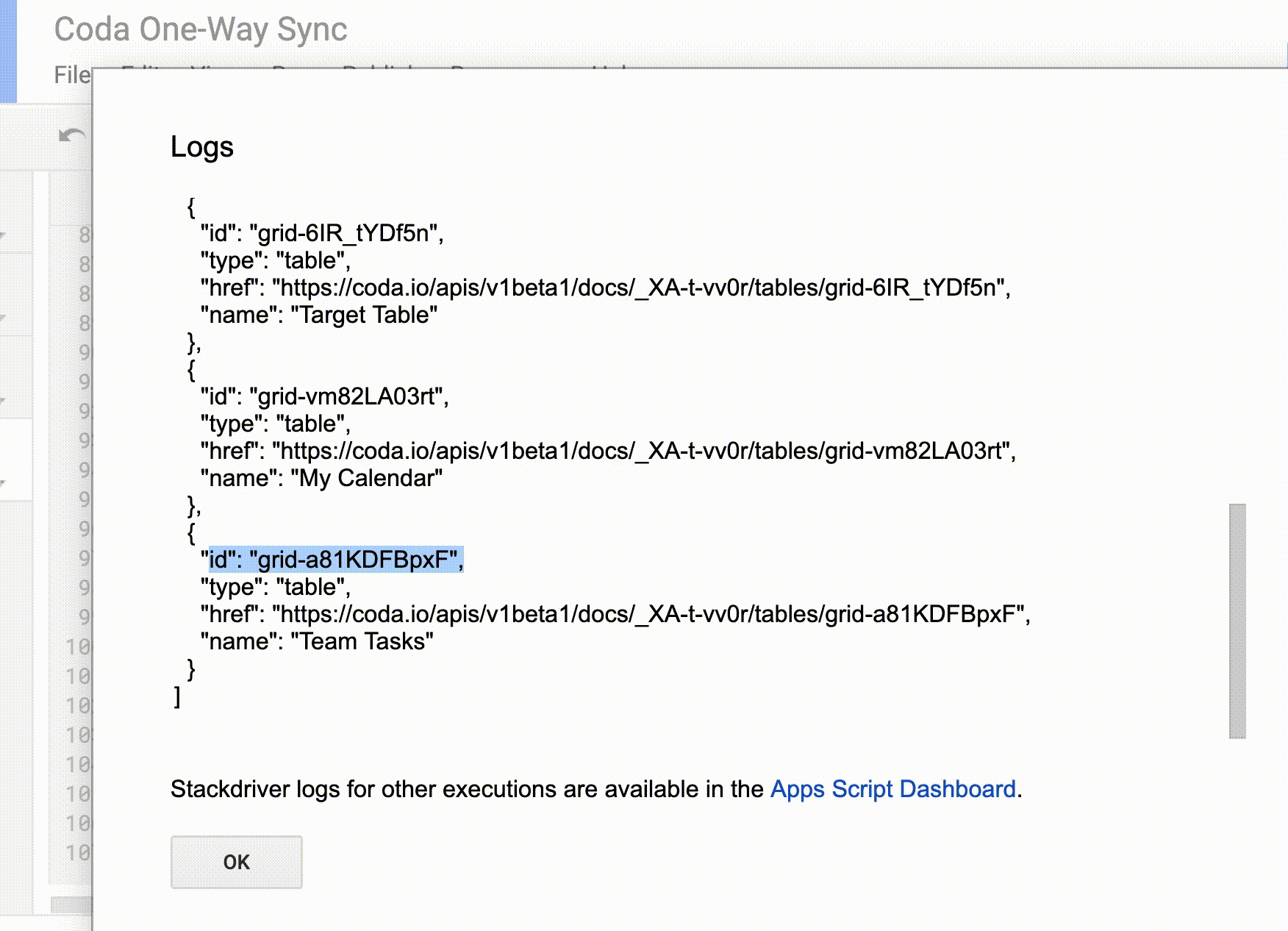
Retrieve table IDs using the printDocTables() helper function
Advantages of syncing your Coda tables with GAS
Disadvantages of syncing with GAS
Syncing data between Google Sheets using Google Apps Script
The script for syncing data between your Google Sheets is much shorter (but also comes with a few drawbacks):
var sourceSpreadsheetID = "TO UPDATE";
var sourceWorksheetName = "TO UPDATE";
var targetSpreadsheetID = "TO UPDATE";
var targetWorksheetName = "TO UPDATE";
function importData() {
var thisSpreadsheet = SpreadsheetApp.openById(sourceSpreadsheetID);
var thisWorksheet = thisSpreadsheet.getSheetByName(sourceWorksheetName);
var thisData = thisWorksheet.getDataRange();
//Uncomment line 11 below and comment out line 9 if you want to sync a named range. Replace "teamBugs" with your named range.
//var thisData = thisSpreadsheet.getRangeByName("teamBugs");
var toSpreadsheet = SpreadsheetApp.openById(targetSpreadsheetID);
var toWorksheet = toSpreadsheet.getSheetByName(targetWorksheetName);
var toRange = toWorksheet.getRange(1, 1, thisData.getNumRows(), thisData.getNumColumns())
toRange.setValues(thisData.getValues());
}
Instructions to run the script

Google Sheets ID is after the “/d/”
2. Get the sheet name from the source spreadsheet and target spreadsheet and paste them into the sourceWorksheetName and targetWorksheetName variables, respectively.
3. (Optional) If your data in your source spreadsheet is a , comment out and un-comment and replace teamBugs with the name of your named range.
Advantages of syncing your Google Sheets with GAS
Disadvantages of syncing your Google Sheets with GAS
GAS copies data from the source and pastes in the target

Unlike Coda’s API, there is no native row identifier in Google Sheets. Some people have built to generate random IDs. Without the Source Row URL like we have in Coda, the GAS script essentially copies the values from your source spreadsheet and pastes them into your target spreadsheet. It’s a clean wipe of your target spreadsheet which is not the best solution if you have added columns with custom formulas in your target spreadsheet (see bullet point # from the Disadvantages of syncing your Google Sheets with GAS above).
While the sync is a bit snappier than the sync using Coda’s API, syncing Google Sheets with GAS is not as precise given the lack of unique identifiers for columns and rows in the source and target spreadsheet. You could, of course, write a custom formula that creates a unique identifier, but then you have to “store” that identifier in a hidden column or row in the spreadsheet, or perhaps store it in the GAS script itself.
In most businesses, the data set is usually growing in the number of rows and columns. If the schema in your source data set in the source spreadsheet is staying fixed (e.g. no new columns will be showing up), then the GAS script for syncing your Google Sheets should be sufficient for your needs. You could get fancy and add the named range to account for new columns showing up in your source spreadsheet. With this solution, however, you can’t add any columns to the target spreadsheet (on the sheet where the data is syncing). Otherwise, your custom columns will be overwritten.
For example, my “Team Project Tracker” source spreadsheet has a bunch of bugs my team is tracking:

Source spreadsheet with a bunch of team bugs
The first time I sync the data to another spreadsheet called “My Stuff,” everything copies over correctly. I decided to create a column called Bug ID Number in column J where I just take the number from the ID column using the mid() function:

Target spreadsheet where I added a custom formula to column J
Now back in my “Team Project Tracker” spreadsheet, I realized I needed to add a Due Date column and I insert it after column A, shifting all my columns over by 1:

I added a new “Due Date” column in column B
Want to print your doc?
This is not the way.
This is not the way.
Try clicking the ⋯ next to your doc name or using a keyboard shortcut (
CtrlP
) instead.